
深圳市哲瀚電子科技一級代理OCX系列產品:低壓LED驅動系列OC1002 OC4000 OC4001OC5010OC5011 OC5012 OC5020BOC5021BOC5022BOC5022 OC5028B OC5031 OC5036 OC5038 OC5120B OC5120 OC5121 OC5122A OC5122 OC5128 OC5136 OC5138 OC5330 OC5331 OC5351 OC5501 OC5620B OC5620 OC5622A OC5628 OC6700B OC6700 OC6701B OC6701 OC6702B OC6702 OC6781OC7130OC7131 OC7135 OC7140OC7141電源管理系列OC5800L OC5801L OC5802L OC5806L OC5808L OC6800 OC6801 OC6811 高壓LED驅動系列OC9300D OC9300S OC9302 OC9303 OC9308 OC9320S OC9330S OC9331 OC9500S OC9501 OC9508等更多型號,提供方案設計技術支持等,歡迎來電咨詢0755-83259945/13714441972陳小姐。
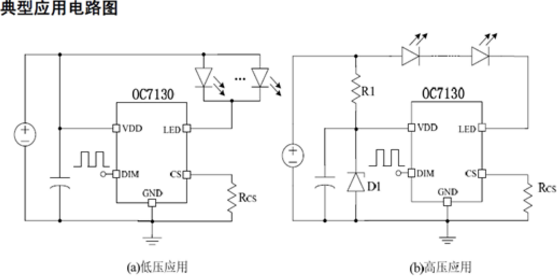
OC7130是一種帶PWM 調光功能的線性降壓LED恒流驅動器,僅需外接一個電阻就可以構成一個完整的LED 恒流驅動電路調節該外接電阻可調節輸出電流,輸出電流范圍為10~2000mA。
OC7130 內置30V 50 毫歐MOS。
OC7130 內置過熱保護功能,可有效保護芯片,避免因過熱而造成損壞。
OC7130 具有很低的靜態電流,典型值為49uA。
OC7130 帶PWM 調光功能,可通過在DIM 腳加PWM 信號調節LED 電流。OC7130 采用ESOP8 封裝。


1.內置 30V 50 毫歐MOS
2.低靜態電流:49uA
3.輸出電流:10mA 到2000mA。
4.PWM 調光:最高頻率10KHz
5.輸出電流精度:±4%內置過熱保護
6.VDD 工作電壓:2.5-6V
1.線性 LED 照明驅動
2.LED 手電筒、LED 臺燈、LED 礦燈、
3.LED 指示燈等
升壓恒流:
OC6701 3.2~100V 大于輸入電壓2V以上即可3A以內
OC6700 3.2~60V 大于輸入電壓2V以上即可 2A以內
OC6702 3.2~100V 大于輸入電壓2V以上即可 1A以內
降壓恒流:
OC5021 3.2~100V最少低于輸出電壓1V以上就可以正常工作5A以內
OC5020 3.2~100V最少低于輸出電壓1V以上就可以正常工作 2A以內
OC5022 3.2~60V 最少低于輸出電壓1V以上就可以正常工作 3A以內
OC5028 3.2~100V 最少低于輸出電壓1V以上就可以正常工作1.5A以內
OC5011 5~40V 最少低于輸出電壓1V以上就可以正常工作5A以內
OC5010 5~40V 最少低于輸出電壓1V以上就可以正常工作2A以內
LED DRIVER DC-DC升降壓恒流
OC4001 5~100V 3.2~100V 3A
LED DRIVER DC-DC線性降壓恒流
OC7135 2.5-7V 低于等于輸入電壓即可固定<400mA
OC7131 2.5-7V 低于等于輸入電壓即可 可外擴,實際電流決定于MOS管功耗
OC7130 2.5-30V 低于等于輸入電壓即可 實際電流決定于IC整體耗散功率
LED DRIVER DC-DC降壓恒流專用IC系列:LED遠近光燈專用芯片
OC5200 3.2~100V最少低于輸出電壓1V以上就可以正常工作 2A以內
OC5208 3.2~100V最少低于輸出電壓1V以上就可以正常工作 1.5A以內
LED DRIVER DC-DC降壓恒流專用IC系列:多功能LED手電筒專用芯片
OC5351 3.2~100V最少低于輸出電壓1V以上就可以正常工作5A以內
OC5331 3.2~100V最少低于輸出電壓1V以上就可以正常工作 5A以內
DC-DC降壓恒壓
OC5801 8~100V最少低于輸出電壓5V以上就可以正常工作 3A以內
OC5800 8~100V最少低于輸出電壓5V以上就可以正常工作2A以內
![M`_)HE77EWMP0W}AIF51]HK](http://news.hqew.com/file/Images/error!)
Intel近日在內部發表一篇告員工的內參文章,全文在Reddit上泄露了出來,表示歷經50余年的Intel與AMD的競爭進入了新的階段。AMD和Intel創立時間都在68-69年,兩個公司的位置也十分接近,兩個公司的業務重疊領域也很多,可以說是歷經50年的對手。但在2018年,AMD的銷售額為64.8億美元,員工數10100人,而Intel卻有超過了700億美元的銷售額和超過10萬員工,這兩者之間有著超過10倍的差距。
Lisa Su在擔任AMD CEO的五年就是AMD股價飛升的五年,在這段時間里,AMD股價上升了681%,遠遠跑過Intel和標準普爾的水平。AMD在最近兩個財年增長速度都超過20%,Intel認為AMD作為個強大的競爭對手在重新崛起。之前Intel的Roadmap是一個季度更新一次,但最近一次更新已經過去了快半年,很明顯Intel正在準備從內部重新調整自己的產品策略來應對Zen 2的挑戰。
而作為消費者,我們更為樂于見到AMD的強大,旗鼓相當的相互競爭才能觸動行業的發展。在Zen發布之后,Intel就很明顯的加快了產品規格提升的速度,僅僅兩三年的時間,處理器規模就從7700K的4核心,提升到了9900K的8核心,這在幾年之前是很難想象的。要知道4核心8線程作為非HEDT的旗艦,從2600K到7700K都未曾動搖過,但Zen卻改變了這一切。短短兩年Intel桌面平臺核心數就實現了翻番,現在千元已下的i5就已經有之前i7級別才有的性能和規格。
而在7月7日發售的全新一代Zen 2,也被給予很高的期望。在京東平臺預售3700X的預定量高達4465件,而相同價格定位同期預定的i7 9700F預定量只有36件(截至2019年7月7日8點),其之間有124倍的差距,這作為一顆高端處理器而言實屬不易,看來Zen 2大成功。
Zen的成功是有目共睹,Zen 2的期待情緒也是尤其高漲,但伴隨高漲的情緒奇怪的氛圍也滋長起來,就是對于Zen 2的各種抬高。AFAN群體似乎認為3700X就可以拳打9900K一樣。這樣情況是多種原因導致的,既有錯誤信息引導,也有人蓄意帶節奏。
早些時候晚上有個不明出處的圖,上面寫著3800X頻率可以有4.7GHz,GPU-Z單線程得分可以有635分(但實際上3800X超頻只能有4.3GHz,得分也就520分水平)。
稍后有個Passmark得分上傳泄露,媒體就編撰出《三代銳龍最弱的一顆U:單核滅門9代酷睿》這樣的標題。
到7月7日發布前夕,又有了3600游戲全滅8700K的測試,真是喜聞樂見。
社交媒體和傳統媒體都不自覺的,或者蓄意的抬高對Zen 2的評價,這樣的結果就是導致大眾對于Zen 2存在過高的期待。但這樣的過高的期待,在Zen 2 NDA解除之后同真實性能對比就會形成巨大的落差,期望越大失望也就越大,大眾對Zen 2的認知也會由徹底肯定轉換成對立的徹底否定。這樣的抬高心理預期的信息傳播大多人雖然僅僅是出于娛樂精神,但也不能排除少數人有著不可告知的目的。
而本篇評測的主要目的,就是去偽存真,在本源、應用和市場層次上告訴你Zen 2到底怎么樣,到底值不值得買。
AMD Zen 2 微架構概述在當年 Ryzen 發布會的時候,AMD 已經向媒體公布了 Zen 的接替者 Zen+、Zen2 等后續微架構,和初代的 Zen 或者說 Zen 1 相比,Zen+ 在微架構上的改動非常小。
目前所知的,Zen + 的改進主要是 CPU 的二級高速緩存時延從 17 個周期縮短為 12 個周期以及提升了預拾取,其他的就是靠制程提升頻率以及在內存控制器上改進實現更快內存的支持,IPC(每周期指令性能)的提升只有大約 3%。
相當于 Zen+ 而言,Zen 2 是 Zen 的真正微架構改版,在流水線的前后端都有大幅度的修改,涵蓋了高速緩存、分支預測、新指令支持、執行端口和內部總線的擴充以及外部總線的升級。
按照 AMD 的說法,相對第一代的 Zen 而言,Zen 2 IPC 提升可以達到 15%,作為一個改進型的微架構,這樣的幅度在摩爾定律日益失效的今天而言,是非常可觀的。
接下來的內容可能會有些枯燥、晦澀,但是如果你能靜下心來看的話,還是會比較有趣的,因為我們將探究 Zen 2 這個微架構到底在哪些地方做了改進,而它們又將對哪方面產生影響。
說到這,我覺得需要說明一下,所謂的微架構,是指指令集的邏輯實現,例如功能組織、邏輯設計,一般由架構師來進行這個工作,架構師將研發人員提供各種功能模塊擺在面前,然后考慮到各種(成本、功耗、可用性)妥協的情況下,將它們依據合理的規格組織在一起。
對于我們這些局外人來說,微架構就是一張張的微架構圖,而 Zen1 和 Zen 2 的微架構是長這樣的:

我們都知道,Zen 采用了 CCX 內核復合體的多層次多核技術,每個 CCX 內有 4 個上圖中的 Zen 內核,四個 Zen 內核之間透過一塊 CCX 內的三級高速緩沖實現數據同步、共享,而 CCX 之間的數據同步和共享必須透過名為 IF 的系統總線跑到主內存上進行。
因此,程序和操作系統必須確保相盡可能都在一個 CCX 內進行數據交換才能達到性能最佳化,當然,這個問題其實在 Intel 的一些 Xeno MP 上也是存在的。
我們下面討論的主要集中在 CCX 內部或者說 Zen 2 內核的微架構情況,因為這才是 Zen 2 真正實現更高 IPC 的所在。
Zen 2 微架構改進概覽Zen 2 微內核和 Zen/Zen+ 都同屬一個家族,但是在細節上有很多不一樣的地方:
1、制程:Zen 2 采用了 CPU 內核和北橋片上分離的設計,CPU 內核采用臺積電 7 納米制程(Zen+ 是 12 納米),服務器版(EPYC Rome)的北橋采用格羅方德 14 納米,桌面版(Ryzen 3000)的北橋是臺積電 12 納米。
2、內核:
前端:
改進了分支預測器;
改進了預取器;
改進了微操作標簽;
改進了微操作高速緩沖;
更大的微操作高速緩存(從 2K ops 到 4K ops);
增大了派發帶寬;
后端:
更大的回退(retire)帶寬;
浮點單元:
數據通道提升至兩倍寬(從 128 位增加到 256位);
兩倍執行單元(FMA 指令寬度從之前 128 位增加到 256 位);
位寬加倍的 Load/Store(加載/存儲)單元(從之前的兩個 128 位 L/S 兩個 256 位);
整數單元:
寄存器堆從 168 個增加到 180 個;
增加了一個 AGU(地址生成單元),使 AGU 數量增加到 3 個;
更大的調度器(從 4 個 14 ALU 條目 + 兩個 14 AGU 條目增加到 4 個16 ALU 條目 + 1 個28 AGU 條目);
更大的指令重排序緩存(I-ROB,從 192 個提升到 224 個);
內存子系統:
一級高速指令緩存從 64KiB 縮小到 32 KiB;
一級高速指令緩存從 4 路組關聯提升到 8 路組關聯;
二級數據地址轉譯緩存(DTLB)容量提升到 1.33 倍,達到 2048 個條目(Zen/Zen+ 是 1536 個條目);
存儲隊列從 44 個增加到 48 個;
3、CCX:
三級高速緩存從 8MiB 提升到 16MiB;
三級高速緩存時延性能下降,從 35 周期增加到 40 個周期;
4、安全性:
硬件級抵御幽靈攻擊;
密鑰/虛擬機的支持數量增加;
5、I/O:
PCIE 4.0;
Infinity Fabric 二代:
每通道傳輸率提升到 2.3 倍(10.6 GT/s -> 25.6 GT/s);
內存時鐘 MCLK 與 IF 時鐘 FCLK脫耦,可以實現 2:1 和 1:1 的倍頻率;
支持 DDR4-3200(之前是 DDR4-2933)。
7、指令集:
CLWB:對修改過的高速緩存塊(Cache Block 或者說 Cache Line)進行回寫操作,同時可以將該高速緩存塊保留在高速緩存層次結構中。
WBNOINVD:將內部高速緩存所有修改過的存儲塊寫回到主內存中,但是不將高速緩存標記為無效(也就是不刷新)。
RDPID:讀取處理器 ID。
從列表來看,Zen 2 的變化是幾乎全方位的,前后端、內存子系統、總線系統以及指令集,都為這個微架構注入了新的魔法,其中的三條新增指令對性能的影響不會很大,FMA4 指令也未被重啟,所以我們更多的是關注 Zen 2 微架構的前后端部分。
Zen 2 前端——高速緩存以及分支預測器 微操作高速緩存Zen 的微架構在很多方面都和 Intel 的 Core 系列 CPU 非常類似,例如微操作高速緩沖(μops-Cache,Intel 也稱之為 Decoed Stream Buffer 或者 DSB,AMD 對微操作的簡稱是 OC,而 Intel 對其簡稱是 UC)。
Zen1/Zen+ 的微操作高速緩存大小都是最高 2K 指令,如果按照 AMD 的軟件指南,提到微操作高速緩存的大小是 2KiB(第 2.1 節,p18)。
這個 2KiB 的說法似乎是有點讓人感到疑惑的,因為解碼后的指令或者說微操作都是固定長度的,而微操作的長度不可能只有 1 個字節(8 位)。
相比之下,Intel 的 Coffee Lake(CFL,2017 年第三季發布,就是現在的 9000/8000 系列)微操作高速緩存大小是最高 1.5K 指令,一般認為 Intel 的微操作長度大約是 3 個字節左右。
微操作高速緩存里放的都是循環程序中已經解碼過的指令,這些已經解碼過的指令稱作微操作。
采用微操作高速緩存這樣的好處是在可以簡化解碼器設計的同時維持盡可能高的指令并行度。
要知道 x86 作為一種復雜指令集,其指令長度不是固定的(1 到 17 個字節),所以像 Intel 的多路 x86 解碼器都是采取一個復雜解碼器搭配幾個簡單解碼器的方式。
在微操作高速緩存發揮作用的時候,標準的指令拾取和解碼處理會被繞過。按照當年 Intel 提供的數字,微操作高速緩存的平均命中率可以達到 80%,這意味著在 80% 的時間里,x86 解碼器的耗電都可以節省掉。
Zen 的微操作高速緩存帶寬最高可以做到每個周期 8 條指令,相比之下,Zen 的傳統取指和解碼器只能做到每周期 4 指令。
Zen 2 的微操作高速緩存大小增加到了 4K 指令,兩倍于上一代,這意味著可以提高微操作高速緩存的命中率,改善循環的性能。
不過作為代價,Zen 2 的一級指令高速緩存被減半位 32KiB,作為補償,一級指令高速緩存的組相聯從之前的 4 路或者說 4 組提升到了 8 路,作用是提高一級指令高速緩存的命中率。
TAGE 分支預測器相對于微操作高速緩存,Zen 2 在分支預測上的改進帶來的性能提升可能更大。
現在的處理器都采用了超流水線和超標量設計,流水線上有多個工位負責不同的工作,例如取指、解碼、執行、寫回以及為了提升頻率而加進去的驅動工位,每個內核內都有多條這樣的流水線。
以 Zen 1 為例,它的整數流水線長度大約是 17~19 級工位(17 是微操作高速緩存命中后的情況),如果放在以前的話,這算是很深的流水線了(當年被詬病流水線深度太長的 Pentium 4 大約是 22 級或者 31 級工位)。
更長的流水線好處是縮短每個指令的處理時間,便于實現更高的頻率,但是為了讓流水線保持滿載,必須找出可以在流水線中重疊的不相依指令流,只有這樣才能實現指令并行。
例如流水線中存在條件跳轉指令的時候,由于相依性不確定的緣故,處理器必須等待其通過執行工位后,才能讓下一條指令進入取指工位。
下圖所示的,就是經典的四級工位流水線(取指、解碼、執行、寫回)在遇到分支時遭遇到的流水線工位停擺動畫示例(垂直方向是流水線工位狀態,水平方向是時間周期):

如上圖所示,這是一條可以每個周期執行一條指令(1 IPC)的四級工位流水線,當出現條件分支指令的時候,第一條指令和第二條指令之間的流水線停擺周期會達到兩個周期,相當于損耗了 50% 的性能,流水線中出現停擺工位的情況,有時候被稱作“氣泡”,這里就是有兩個氣泡。
為了降低分支導致的性能損失問題,人們提出了預測分支行為的技術,而在處理器中實現這個功能的單元就是分支預測器(Branch Predictor)。
依然以上面的四級工位流水線為例,看看有了分支預測器后,條件分支不被選中的情況:

可以看到,流水線保持著充盈運作狀態,3 條指令用了七個周期來完成,而之前是需要 9 個周期,第一條指令和后續指令是緊挨著運行的。
不過分支預測也不是每次都準的,像靜態分支預測也就是 80% 的命中率,即使如此 20% 的預測失敗率對性能也是有巨大影響的,因此人們又提供了動態分支預測,例如 2-bit 狀態機,就是使用單個分支的最近行為來預測該分支的未來行為。
由于流水線工位越來越多(越來越長),分支預測失敗造成的性能影響與日俱增,因此動態分支預測器的開發一直是微架構比較重大的研發課題,但是這方面進展其實比較慢。
時至今日,人們還在為最后的 3% 成功率拼盡全力,因為現在想要提高 1% 的命中率往往意味得在前人的基礎上再減少 30% 的誤預測率,這是一個巨大的挑戰。
Intel 公司最近發表了一篇名為《Branch Prediction Is Not A Solved Problem: Measurements, Opportunities, and Future Directions》的論文,開篇就提到:
“For example, we show that correcting the mispredictions made by the state-ofthe-art TAGE-SC-L branch predictor on SPECint 2017 would improve IPC by margins similar to an advance in process technology node.”
大意就是,在 SPECint 2017 這個業界認可的基準測試中,采用最新式的 TAGE-SC-L 分支預測器達成的誤預測糾正能力,可以達到的每周期性能提升幅度相當于提前使用了下一代節點制程。
Intel 就是這么認為的,并且很可能已經在其處理器中采用了類似于 TAGE 的概念,相關的論文也表明,Intel 在 TAGE 有一定的參與度。
TAGE 預測器的全稱是TAggedGEometric history length branch predictor,直譯過來就是標記幾何歷史長度分支預測器,由兩級分支預測器組成。一個是常見的基本預測器,用于提供默認的預測,另一個其實一組標記預測器,提供一個只符合一個標記的預測結果。
TAGE 分支預測器及其衍生的設計自從 2006 年的 CBP-2(第二屆分支預測冠軍賽)以來,一直都位居冠軍榜單上,從未丟過桂冠,其優勢就是成本效益比,在 06 年推出的時候,就憑借同樣的芯片面積預算,以顯著的優勢擊敗了 04 年 CBP-1 里出現的所有分支預測器。
分支預測器很重要,而 TAGE 分支預測器是目前最好的分支預測器,如今 Zen 2 也引入了這個最好的分支預測器。
Zen 1 的分支預測器沿用自針對低功耗處理器 Jaguar 的分支預測器,AMD 對其命名為神經網絡感知分支預測器,不過 Jaguar 的流水線深度只有 14 級,Zen 是 17-19 級流水線深度。按理說流水線越深,分支預測失敗的懲罰就越高,因此對分支預測器的性能就越高,事實上除了流水線深度外,Zen 2 的超標量能力也是遠高于 Jaguar 的,這會進一步增大分子懲罰的幅度,故此神經網絡感知分支預測器對 Zen 來說是有點拖后腿的。
為此,AMD 在 Zen 2 上采用了兩級分支預測機制,原來的神經網絡感知預測器依然保留作為一級分支預測器,而 TAGE 則被引入作為二級分支預測器。
我們在上面啰嗦了一大堆東西,到底在實際應用中會有多少的性能變化呢?我們在這里使用 Fritz Chess benchmark 也就是大家眾所熟知的國際象棋來做一個對比。
國際象棋是一個有密集分支指令的應用,當初我使用這個測試軟件的,目的是為了對比流水線 31 級的 Pentium 4 和流水線 12 級的 AMD Athlon X2 5000+(K8 系列 Windsor 微架構,90 納米制程)的,下面這個圖表可以讓大家回憶一下當初這兩個產品的性能對比:
Pentium 4 家族使用的甚深流水線設計使其分支預測失敗導致的性能損耗遠高于 K8,在 Fritz Chess Benchmark 中,這個問題會被顯著放大,上面的測試結果表明這是一個比較適合用于測試分支預測損失的測試。
為了確定流水線深度的影響,我覺得有必要看看 Zen 2 的流水線深度到底是多少級的。
AMD 和 Intel 沒有公布過新近處理器的流水線深度,不過我們可以透過測試分支預測失敗的懲罰來獲知。
上表中的左側是以偽代碼方式提供分支程序測試片段,以第 7 個測試(Test 6)為例:
Test 6, N= 1, 8 br, MOVZX XOR ; if (c & mask) { REP-N(c^=v[c-256]) } REP-2(c^=v[c-260])
這段內容包含了一個 MOVZX 內存載入操作指令,它需要額外的 5 到 6 個周期來執行,在支持亂序執行、亂序 L/S 的處理器中,這個動作通常會被掩蓋掉。
從上圖中可以看到,這個 Test 6 的 Zen 2/Zen 1 測試結果分別是 12.22/12.30 個周期,加上 MOVZX 的 5 個周期,那這個測試的 Zen 2/Zen 1 有效結果就是 17 個周期。
從測試結果來看,Zen 2 的分支預測懲罰都在 17-19 個周期左右,Zen 1 則是 17-21 個周期左右,Coffee Lake 和 Kaby Lake 都是 16-20 個周期左右。我們認為 Zen 2 在流水線長度上和 Zen 1 都是類似的,即 19 級工位(stage),由于微操作高速緩存的原因,有時候可以視作等效 17 級工位。
Zen 2 和 Coffee Lake 的流水線深度也非常接近,也就是一個工位的差別,因此,只要我們測試的時候,兩者的頻率盡量設置到一致(鎖定 4GHz,減少頻率波動干擾,內核數設定為一個,關閉硬件多線程),運行 Fritz Chess 的結果就可以高度反應兩者的動態分支預測性能差別。
TAGE 分支預測器對 Zen 2 的性能提升毋容置疑,但是另一方面,所有的處理器都非常依賴高速緩存。
所有的處理器都采用了多層次內存子系統,而靠近內核的則是高速緩存,Zen 2 和 Zen 1 一樣采用了三級高速緩存設計(微操作高速緩存如果算是零級的話,那可以算是有四級高速緩存),每個 Zen 內核都有自己獨立的 L1/L2 高速緩存,CCX 內的四個內核透過 L3 高速緩存共享、交換數據。
首先讓我們來看看帶寬部分:
我們的內核微架構測試,都是在 BIOS 內設置單內核、關閉多線程,關閉電源管理,強制 4GHz,內存設置為 DDR4-3200 的情況下測試,目的盡量直接探究每個內核的微架構細節。
說明一下的是,由于受到 Excel 的限制,橫坐標的數字格式不支持二進制(如果你有辦法實現的話不妨留言告知),你在圖表看到的橫坐標值都是十進制值,所以單位標注都是 KB、MB 這類十進制單位,而非二進制的 KiB、MiB,圖中的 33KB 標注,相當于 32KiB,34MB 相當于 32MiB,如此類推不一而足。
從測試結果來看,Zen+/Zen 2 這邊的 L1/L2/L3 高速緩存讀取帶寬可以一直保持在每周期 32 字節的水平,而 Coffee Lake 雖然紙面上說 L2 Cache 的 Load 帶寬是每周期 64 字節,但是我們并未從測試中看到這樣的情況出現。
數據高速緩存時延測試
Zen 2 和 Zen+ 數據高速緩存的時延曲線非常類似,不過 Zen 2 由于更大的三級高速高速緩存而在 8-16MiB 的位置有更好的表現。
Coffee Lake 在 32KiB 以內都能保持 4 周期的時延,但是在之后到時延表現都不如 Zen 2。
Zen 系列的 L2 Cache 的時延無法維持在一個穩定的平臺,但是可以在 256 KiB 前都維持比對手更低的時延曲線。
指令解碼/緩存/執行能力眾所周知,x86 是復雜指令集架構,但是和精簡指令集相比,區別并非什么指令數量的多寡,而是其指令長度格式不一。
以最簡單的 NOP 空指令為例,它的 x86 編碼長度是一個字節,加法指令 ADD、乘法指令 MUL 等則是兩個字節,最長的 x86 指令有 17 個字節。
我們采用了部分有代表性的 x86 指令進行指令解碼測試,測算出解碼帶寬信息(結果受微操作高速緩存、指令高速緩存、解碼器、執行單元、回退等工位影響):
正如你所看到的測試結果,Zen2/Zen + 都具備每周執行 5 個單字節指令的能力,而 Coffee 則是只有每周期 4 單字節指令的能力。
Prefixed CMP 其實是針對 x86-64 指令的測試,可以看到,在微操作高速緩存范圍內的指令流能夠為處理器維持每周期 4 條 8 字節指令的執行能力。
如果單純從表格來看的話,Zen2 似乎和 Zen+ 一樣,但是我們將收集的數據整理為圖表后,看到了更多的細節:
我們選取了 NOP 指令(x86 指令長度 1 個字節)以及 Prefixed 的 CMP 4(x86 指令長度 8 個字節)的測試結果做了上面的兩個圖表。
可以看到 Zen 2 在 NOP 的時候,每周期 5 指令的峰值數據可以維持到 3KiB 以上,而Zen+ 只能維持到大約 0.2KiB 左右。
在長度為 8 字節的指令時,Zen2 每周期兩指令的峰值數據可以維持到 16KiB,而 Zen + 只能維持到 8KiB。
從目前的測試結果來看,我們估計 Zen2 的微操作高速緩存容量按照字節衡量的話,應該不低于 16KiB。
微架構實現細節對比
我們使用 AIDA64 v6.00.5122 Beta抓去了 Zen 和 Zen2 的指令時延、吞吐率,其中 Matisse 就是 Zen2 的桌面版內核微架構版本代號。
上表中的 MOV r32 到 VPCLMUL 等指令就是從其中 4000 多條指令測試項目中提取出來的有代表性的測試結果,豎線的兩側分別是時延和吞吐率,單位是周期,因此吞吐率其實是 CPI 值,即周期/指令,是 IPC 的逆向表示方式。
其中涉及到 ymm 寄存器的測試都是 AVX2 256-bit 指令。
從測試結果來看,Zen 2 的 AVX2 ADD/MUL/FMA 等指令的吞吐性能較 Zen 提升了一倍,證明 Zen 2 的確在 AVX2 實現上有做改進。
Zen 2 內核微架構總結從微架構角度看,Zen 2 的最大改進是對前端單元的加強,包括引入了目前幾乎最強大的動態分支預測器 TAGE 分支預測器作為第二級分支預測,使得 Zen2 可以在分支密集型的應用中比上一代的 Zen+ 快 20%。
即使和 Coffee Lake 相比,同頻下的 Zen 2 在分支密集應用中也能快 5%,這是多年未曾出現過的現象,上一次在這類測試中出現 AMD 比 Intel 快的時候是因為比對手短 50% 流水線深實現的。
而這次是雙方流水線深度相當的情況下,憑借動態分支預測器實現,對于未來數年 AMD 的競爭前景意義更大,現在的情況就好像兩個槍手對決,拔槍速度相當,但是 Zen2 的槍法很可能更準。
Zen 2 的微操作高速緩存達到 4K(微操作),從上面的解碼帶寬測試來看,我們認為這個改進對于有大量循環的應用會有一定的改進。
由于兩個向量單元引入了 256 位 AVX2 指令單周期執行能力,Zen2 在計算吞吐能力比上一代微架構提升了一倍,達到了和 Coffee Lake 相當的水平,x265 這類引入了 AVX2 優化的應用將會受益。
Zen 為 AMD 從頹勢中重新找回與對手競爭的信心,Zen+ 為 AMD 取得了市場,而 Zen 2 則是 AMD 讓我看到了真正翻身的希望。
這次應該可以至少堅持到 Intel 的 Comet Lake,嗯,時間窗口有半年,能爽半年還是不錯的。
NB的回歸
前面部分是微架構部分,后面就是相對宏觀的平臺架構部分。
NB是什么意思?就是North Bridge的回歸,北橋的回歸。年輕的朋友可能不知道北橋是什么?現在一般把PCH叫做南橋,是因為很久以前還有個芯片叫做北橋。上面的965芯片組的華碩P5B-Deluxe,和供電散熱片由熱管相聯的芯片就是北橋。(為什么選這個主板?因為我十幾年前我自己用的這個)

上面就是個典型的北橋芯片布局圖,CPU通過FSB前端總線連接北橋,而內存和PCI控制器這些高速接口都在北橋里,而南橋主要負責串口,USB、SATA這樣的低速設備。此外白橋還有個特征,就是北橋是通過Front Side Bus前端總線和CPU相連,并且之間的連接速率并不是全速,而是和外頻成倍數關系。如我之前的Core 2 E6300外頻是266,FSB是X4 1066MHz,倍頻是7,那處理器頻率是266×7=1.86GHz,而我超頻可以將外頻提升到500,達成500×7=3.5GHz。
Intel這邊最后保持完整北橋的芯片組是Core 2的P45/X48這代,之后的X58雖然保持北橋,但其實主要是控制PCIE,而內存控制器已經集成到CPU內部了。而AMD這邊則更早,Athlon 64就已經開始在CPU內部集成了內存控制器,北橋主要是連接高速PCIE。
而到Sandy bridge的P55這代,內存控制器和PCIE控制器都集成到了CPU內部,全集成相比獨立的北橋速度更快,延遲更小,北橋和前端總線似乎就要徹底的離開歷史舞臺了。
但到了Zen 2,北橋似乎就回歸了,內存控制器和PCI控制器和CPU雖然還是在一個基板上,但是分開封裝,并且通過異步的總線進行連接。就是說Zen 2又回歸到到K8以前傳統的架構。
Zen 2的設計將內存控制器,PCIE控制器等部分從核心中拿出,核心/緩存被集中在Chiplet芯片里,而互聯部分的IF總線,內存控制器、PCIE/NVME/SATA、時鐘生成器和其他IO部分則被放在名為cIOD的芯片里(北橋),其通過Infinty Fabric總線進行連接(FSB)。
再來看看具體的設計。單個核心的封裝名為CCD,每個CCD里面有2個CCX,每個CCX里面可以有4個核心,16MB L3緩存。每個CCD同cIOD的連接位寬為32B/周期。cIOD里的Data Fabric到內存控制器的位寬也是32B,這和到核心的位寬一樣。
Fabric總線的速度和內存控制器可以同步和異步,在1200-1600MHz范圍是同步,如果用戶內存是2133MHz,那內存控制器速度就是1066MHz,但Fabric總線還是會保持1200MHz的最低速度,如果在內存在2400-3600MHz范圍,Fabric總線的速度和內存控制器同步就是內存速率的一半。內存單通道是8B,雙通道就是16B,但由于DDR Double后頻率翻翻,但位寬只有Data Fabric到內存控制器的位寬一半,這樣帶寬剛好保持一致。
如果內存速度高于3600MHz,那Fabric總線的速度和內存控制器就最高固定在1800MHz。默認設置Fabric總線最高可以運行在1866MHz,如果內存頻率高于1866X2,那Fabric總線和內存控制器就是異步模式,內存控制器的速度減半,如4000或者4266,內存控制器頻率就是半速的1000/1066,那Fabric總線就會是異步模式,保持1800的頻率。
例如內存頻率在4266 MHz,16B帶寬就是68GB/S,內存控制器的頻率是半速,才1066MHz,32B帶寬是34GB/S,異步的IF總線是1800MHz,32B帶寬是57.6GB/S,明顯內存控制器會成為瓶頸。這個時候內存延遲就會反而增加,并進一步影響到帶寬(后面會有具體測試)。內存的延遲增加,其實也減輕了內存顆粒的負載,反而使得Zen 2內存比較容易上高頻。但這樣的高頻并沒有什么意義,帶寬和延遲反而會變差。對于Zen 2而言,3733MHz就是甜點頻率,如果可以達到這個頻率,就應該考慮的是縮小參降低延遲,綜合考慮性價比,AMD官方推薦是3600C16的內存規格。
但更為細致的手工調節,我們可以在同步模式將IF頻率拉到1900,內存運行在3800,這個時候內存控制器依然是同步模式。其實更為準確的說,只要是內存頻率/2等于IF頻率的同步模式,內存控制器依然是全速,因此追求最佳效能,可以同步拉高IF和內存頻率。但從現在的情況看,IF可以提高的余地大概只有33MHz,從1866到1900MHz。
我們使用AIDA64 6.0測試不同內存頻率的延遲,內存頻率高于3733以后,內存延遲就會大幅升高。Zen 2的內存延遲要高于Zen/Zen+,不過這在預料之中,內存控制器在iCOD里,需要通過IF再到MC,路徑更長,符合預期。
內存讀帶寬在3733之前是逐步走高,但超過3733,內存帶寬會斷崖式下跌,在3733之前實際帶寬是理論帶寬的87%,而超過3733,帶寬效率也大幅下降。
另外一點就是寫帶寬,對于只有一個CCD的型號,如3600/3600X/3700X/3800X,其寫帶寬大概只有讀帶寬一半多一點的水平,而2CCD的3900X/3950X內存寫帶寬則是正常平衡水平。AMD給出的解釋是:
Zen2中執行的區域和性能優化之一是將寫入帶寬從CCD->IOD從32B/cyc降低到16B/cyc,而讀取帶寬保持在完全32B/cyc。由于客戶機工作負載不需要做很多編寫工作,所以不需要指定寬度為32B的鏈接。這節省了在其他地方進行有用的優化所需的面積和能量。
我們依然用Cache 2 Cache測試單CCD的3700X L3一致性耗時,IF頻率還是和遠端核心L3耗時相關,IF頻率越高,遠端耗時就越短,內存頻率超過3733進入異步模式,耗時還是和IF頻率相關,和MC無關。Zen 2的耗時相比Zen和Zen+還是有一定幅度的進步。
現在計算機的接口,本質都是PCIE的各種轉接。USB 3.0是,SATA3是,M.2是,DisplayPort也是,TBT3同樣是,差別就是占用的帶寬和物理定義不一樣,但底層都是PCIE。Zen 2的IF頻率按1600MHz計算的話,到IO Hub的位寬是64B/周期,這樣就是102GB/S的總帶寬。PCI-E 3.0 1X的帶寬是1GB/S,X570支持PCIE 4.0,那一個Lane就是2GB/S,102GB/S帶寬就可以滿足50個PCIE 4.0 Lanes的需要,這樣就使得Zen 2+X570有人以往HEDT平臺才有的擴展性能。
這樣大的帶寬分配起來就更加自由,以ROG CROSSHAIR VIII HERO (WI-FI)為例,CPU有組直連的16X PCIE 4.0(可以分拆成2個8X),一組直連的4X NVME和4組USB 3.2 Gen2。4X PCIE帶寬從ICOD連到南橋,再對各種USB、SATA,WiFi,PCIE 1X 4X的擴展就更為從容不迫了。
在這強大的擴展性能之中,最為關鍵的就是PCIE 4.0,Zen 2平臺配合X570芯片組主板的PCIE 4.0可以提供兩倍于PCI 3.0的帶寬。目前支持PCIE 4.0的設備主要有兩個類別,第一是AMD自家的Radeon 5700顯卡,第二類是PCIE接口的SSD。其實現在階段我個人并不看好PCIE 4.0的應用,主要理由如下:
Intel幾乎沒有計劃支持PCIE 4.0(特別是在消費級),而是準備跳過直接在2021年后直接上PCI-E 5.0,并且主要是在服務器領域,而非消費級,AMD方面也只有高端的X570支持,這樣使得PCIE 4.0平臺在未來一段時間不可能形成足夠的市場保有量,下游廠商就會缺乏動力,形成不了生態,PCI-E 4.0雖然是PCIE-SIG的標準接口協議,但在缺乏Intel支持的情況下,依然只是AMD的私有協議;
顯卡方面目前只有AMD 5700系列支持,我們對5700/5700XT的PCIE 3.0和0進行了對比測試:
我測試PCIE 3.0到4.0帶寬從13.76提升到了24.9,提升幅度基本有81%,這個數據比AMD官方PPT的21.8要高14.2%,估計是我這邊IF頻率高的關系。但具體性能我們使用3Dmark timespy的圖形分進行對比,提升僅僅只有0.6%,這點差距僅僅是誤差范圍。并且在之前我skylake-X Refresh的測試中,性能更好的RTX2080TI PCIE 3.0 8x相比16x的性能損失微乎其微,現在對于RTX2080TI這樣的顯卡PCIE 3.0 16X并不是瓶頸,再把帶寬翻翻實際上也邊際效益也不會明顯,更不用說RTX060 Super性能級別的5700XT了。
不過PCIE 4.0對于5700XT CrossFire還是有一定的收益,在雙卡情況單卡降低到PCIE 4.0 8X,但這個帶寬依然相當于PCIE 3.0 16X。3Dmark圖形分PCIE 4.0雙卡提升98.13%,大門PCIE 3.0雙卡提升93.66%,PCIE 4.0在CF效能下還是有接近5%的優勢。‘
儲存方面雖然群聯的PS5016-E16主控方案能夠支持PCIE 4.0 4X,并且借此可以獲得更高的順序讀寫性能。但對于SSD而言,順序性能卻不是性能痛點,痛點在于低隊列深度 的4K性能。并且目前計劃采用PS5016-E16主控方案的都是如技嘉、影馳、威剛,海盜船這樣的二三線SSD品牌,一線的如Intel,三星、西數、東芝、鎂光均沒有推行PCIE 4.0 SSD的計劃。
另外再提一下,PCIE 4.0也并不是Zen 2首發,IBM 早在2017年的Power 9就已經支持PCIE 4.0。
不過他主要是用在提升infiniBand互聯的帶寬,基本可以將帶寬從200GB/S翻翻到400GB/S的水平,這對于依靠infiniBand節點互聯的HPC可以說意義重大,是立竿見影的剛需,而Volta顯卡連接則是用的NVLink。Intel在2020年以后PCIE 5.0首先上在服務器領域也是出于互聯帶寬方面的考慮。
Zen 2的Chiplet部分是采用的7nm工藝,面積為7.67×10.53=80.76mm2(官方數據為77mm2),是右側比較小的那個芯片,左邊比較大的是IO芯片,采用的是更為老舊的12nm工藝,面積為9.32×13.16=122.65mm2(官方數據是125mm2)。
做Chiplet的意義不在于性能,而在于成本,首先是研發成本,相同設計的芯片可以靈活組合滿足不同規模的性能需要,生產上也同樣簡化。此外更大的影響在良品率,先不考慮CIOD的話,如果做一個包含8個CCX大核心的話,面積大概就需要148mm2(簡單化估算),按照上面的經驗模型曲線這個面積的單個大芯片大概只有27%的良品率,而做4個CCX的74mm2的小芯片大概是38%的良品率。假設一個晶圓可以切割50個大芯片,100個小芯片,那只有13.5個大芯片可以用,而2個一組的小芯片則有19個可用,相同成本的情況下,2個一組的Chiplet設計可以比單個的大芯片多40%的良品。
上面的情況只是簡化的經驗數據,實際上Zen 2還有分離的CIOD芯片,這部分對于性能要求更低,可以使用更為便宜的12nm工藝,再切Zen 2采用的7nm是新工藝在高性能領域的首次應用,實際的良品率情況比上面的經驗模式更為糟糕,那做Chiplet的意義就更為明顯。
再來說說工藝問題,Zen 2是首個采用7nm工藝中央處理器,按照臺積電的說法,7nm相比之前的16nm+(Zen+的12nm并不是指真的線寬,而更多是市場宣傳的營銷手段,只不過是16nm的加強版),功耗僅為60%,性能提升30%,芯片面積縮小70%,那工藝上是不是吊打Intel祖傳的14nm++呢?
Zen 2的CCX面積是31mm2,相比Zen+的44mm2小了29%,這還是處理器規模增大,L3緩存翻翻的情況下達成的。2700X的核心面積大概是193mm2。6/8核心的單CCD型號,Chiplet 77+ iCOD的125=202mm2,如果是雙CCD的12/16核心型號,那核心面積是。Chiplet 77×2+ iCOD的125=279mm2。9900K的核心面積大概是173mm2,單CCD型號在Chiplet使用7nm沒有集成顯卡的情況下,面積依然要大于9900K,而更不用說晶體管規模。雖然CIOD的12cm工藝比較便宜,但7nm的Chiplet生產成本應該會很高,因此Zen 2雖然采用了Chiplet這樣降低成本的設計,但整體成本依然不低。
我們再來看看AMD和Intel各家對于自己工藝性能的描述:
AMD PPT里7nm的每W是差于Intel 10nm的。AMD在Zen 2評測指南里的具體說法是每W性能相比Zen+增加75%,相比Intel 14FF+的處理器提升58%。。
Intel自己PPT里,雖然首代10nm的工藝的密度更高,但晶體管性能14FF++比首代的7nm更好。我們可以注意AMD一直強調的是性能功耗比,而Intel強調的是絕對性能,這個性能就是上高頻的能力。
現在的TSMC 7nm只是采用Finfet+SAQP,充其量只能算是過渡工藝,其首先只是為密度和功耗優化,而不是性能,而后面7nm HP才是完全體,雖然晶體管密度有所下降但性能會大幅提升。想想Intel 5775C的14nm和9900K的14FF++的差別,你大概就能明白,雖然同是14nm,但不能同日而語。
成本除了處理器本身的成本,還有平臺的成本。雖然Zen 2可以在舊有的300/400系列平臺上使用,但想要支持Zen 2更多核心數量的處理器、PCIE 4.0,更高的擴展性、更高的內存頻率,則需要X570才能充分發揮優勢。
但更多核心/更高頻率的處理器需要更多的供電相數和供電散熱,之前的B350/B450入門規格僅有4-5項供電,高階的X370/X470也就8-12相,但Zen 2高階型號已經12-16核心,而且頻率更高,對于供電有更高的要求,X570供電基本是8+4起步,而高階的C8H/C8F都是14+2供電,也遠高于上一代C7H供電規格要高上不少。
PCI E 4.0,更高內存頻率和更大的處理器功耗需要更為復雜的布線更多的PCB層數,X470/Z390基本是入門4層PCB,Hero以上級別6層,但到了X570起步是6層,高階的Strix-I/C8H/C8F/C8I都是8層PCB。另外更大的HUB帶寬,使得可以支持更多的接口設備,X570后擋板各種USB 3.1 Gen2,密密麻麻,相比Z390/Z470也更為充實。
我們比較Strix-E/F級別的Z390,X490和X570,無論是供電規模,還是裝甲覆蓋,毫無疑問都是X570要奢侈的多。并且還提供了雙網卡接口,Q-Code Debug燈和4組AURA接口,之前這樣的待遇要到Hero級別才有。
當然這樣的奢侈用戶也需要付出更高的代價,同級別的X570相比Z390要貴上不少。上面是7月3日京東到手價對比。但換個角度看,X570的PCB、供電,接口規格完全可以越級媲美高一個級別的Z390/X470,綜合而言還是貴得有道理,可以接受。再說用戶也可以繼續選擇B450或者X470來搭配Zen 2的6/8核心型號,要知道5XX元的B450也可以超頻,有RAID功能,Zen 2平臺的成本也不是沒有選擇的余地。
當然我們本次的評測Zen 2的座駕并不會是入門級的X570-P和TUF,而是ROG CROSSHAIR VIII HERO (WI-FI)。C8H的包裝繼續延續ROG一貫風格,下部有一排Logo,其中AMD 50周年/PCIE 4.0的Logo最為亮眼。
C8H在設計風格上并未延續C6H/C7H的設計,而是將Formula的設計元素下放到Hero,從后IO到南橋散熱片一條整體的鏡面帶將大覆蓋的裝甲代區隔成兩個區域,這樣材質和色彩的變化僅僅用簡單線條就使得整體外觀頗具層次感,而并不需要太多繁雜的裝飾。
再來看看和C7H的對比,C8H整體裝甲的覆蓋面積更大,供電的散熱片也更為厚實。
AM4接口部分,需要注意的是CPU和內存之間的布線由Optimem II升級到了Optimem III,能夠更好支持Zen 2的更高內存頻率,并對雙根內存上高頻進行了優化優先使用2/4 DIMM(),這個部分我們后面具體再說。
24Pin下面是電壓測量點,合適高級玩家,這些人相比傳感器讀數更為相信自己的萬用表。24Pin左側是前置USB 3.1 Gen2 Type-C接口,而右上是開關和重啟物理按鍵,這對于喜歡折騰的裸機玩家很有用。邊緣的兩個白色接口是4pin的AURA 12V和3pin的AURA 5V,這個接口下部還有兩組,Hero級別還算大方,特別是不好串聯的5V有兩個會方便很多。
8組SATA接口,SATA接口下面是流速傳感器,For 高端的分體式水冷用戶。
底部的AURA 12V和5V接口,還有安全啟動/快速重試按鈕,還有LN2液氮模式條線,這些功能是為高端發燒玩家定制,他們在極限超頻時候,需要解禁主板BIOS不必要的禁錮,也需要反復的嘗試和重置,這些小功能可以讓他們折騰方便不少。
板載聲卡依然是SupremeFX S1220,其可以達到113dB線性輸入和120dB輸出的信噪比,同時推動力也比較強,可以直推600-Ohms的耳機。
下面的M.2可以支持22110長度,如PM983大船或者高貴的Intel 905P 380G M.2,
再去掉裝甲的上蓋,我們就可以看見風扇和散熱片。
這個風扇是臺達生產,5V 0.44A,功耗2.2W,采用無刷電機,但實際使用過程轉速并不高,完全察覺不到噪音。
巨大的南橋芯片,有14W的功耗,并沒有X470那樣的頂蓋封裝,這樣更好的能夠把熱量傳導出來。

在主動散熱的加持下,南橋散熱片溫度反而不高,基本不到30度,溫度遠不如旁邊的M.2散熱片。
由于主板正面原件過于密集,供電的主控制芯片ASP1405I被移到了主板背面,通過并聯的方式一共有7+1相CPU+SOC供電(規模等效于14+2),每相一顆IR3555,單個IR3555有60A的供電能力。內存為兩相供電,控制芯片是ASP1103。雖然采用控制芯片和Mosfet型號和C7H一樣,但在規模上提升不少。
供電散熱也十分厚實,不是那種美觀作用的所謂Cover。

Ryzen 7 3800X 超頻4.3GHz烤機,供電散熱片外表溫度也僅為40度,相信配合更為高階的3900X/3950X也不會有問題。
后部IO有2個LAN接口,第一個是通常的Intel I211方案千兆網卡,另外一個是Aquantia AQC-111C 5G網卡。下方紅色的7個USB Type-A和Type-C是Gen 3.2 10Gbps帶寬(其中左邊4個是CPU直連,右邊4個是PCH轉出),上面的4個藍色為普通的Gen 3.1。左側有快速清空CMOS和BIOS直刷的按鈕,這都是ROG Hero以上級別的傳統功能。當然X570也可以支持帶有集顯的APU,但從目標人群看幾乎不會有人會選擇用C8H上集顯,因此其后IO并無視頻輸出接口。
WIFI部分采用的是剛剛發布的Intel AX200芯片,其可以支持Wifi 6,通過MIMUMO可以支持2.4Gb的帶寬,而藍牙5.0的帶寬是4.2的4倍。當然實現性能還是需要路由器和其他設備的支持。需要ROG Rapture GT-AX11000,或者 RT-AX88U這樣的支持WiFi 6的新款路由器才能完全發揮性能。
我們再來看看C8H和C7H的PCB厚度對比,明顯的8層板的C8H要比6層板的C7H要厚實不少。
再來看看燈光效果,之前的C6H/C7H雖然配備了5V AURA接口,但主板自帶燈效還是不可尋址的,只能單色整體變化。而C8H這次主板自帶燈光效果也升級到可尋址,可以展現柔和的漸變色。IO Cover的鏡面區域下方有HERO的字樣。
PCH散熱片上也有個ROG LOGO的燈光區域,但這個區域會被顯卡有所遮擋,無論用戶把機箱放在桌上還是桌下,這個Logo區域都會低于視線位置,被巨大的顯卡遮擋。
我們使用的水冷是九州風神Captain 240 Pro,其可以通過3pin 5V AURA而實現燈光同步。
處理器在7月7日首發的有3600/3600X/3700X/3800X/3900X五個型號,但實際供貨的只有3600和3700X,我們本次評測也主要針對這2個型號。需要注意的是上面的價格僅僅是官方建議零售價,實際到手價格會更低,目前京東的活動Ryzen 5交定金減100,Ryzen 7減200,到了7月7號相信馬云家各種開車價格會更低。
Ryzen 7 3700X和2700X都還是采用AM4接口,封裝也沒任何需求,就是標識方向的箭頭小了很多。
3700X的TDP數字也有點難讓人理解,6核心的3600X 95W,8核心睿頻頻率一樣的3700X反而只有65W,但實際3700X自帶的散熱器規格明顯高于3600X,當然AMD的TDP看看就好。具體的實際功耗我們會在稍后具體測試。
測試平臺
測試內存是芝奇幻光戟DDR4 4266C19 8GBx2,具體參數是19-19-19-39,測試過程我們并沒手動縮緊參數,而采用XMP/DOCP的默認設置,需要注意的是AMD平臺并不支持CL19,CL會被強行降到20。
我們本次測試切換到了新的Win 10 1903重新調整了核心的調度策略,會優先使用1個CCX,在一個CCX用干凈后才會使用其他CCX,這樣的調度策略會減少跨CCX操作,降低延遲。
測試Intel方面處理器我們全部是R0步進,減小Windows漏洞補丁對性能的影響,但從即使用戶使用角度看,我們還是將1903更新到最新版本。這些漏洞問題對于Zen 2處理器要不是不存在,要不是通過硬件方法解決,對于Zen 2處理器性能基本沒有什么負面影響。
具體的測試配置如上,在沒有特別說明的情況下,2700X內存頻率為3466,3600/3700X/3800X為3733。3800X 4.3GHz超頻內存為3800MHz,IF為1900MHz,9900K 5GHz,uncore頻率為4.7GHz。
BIOS/超頻溫度和功耗
DOCP和倍頻調節部分,這方面并沒什么特別,唯一需要提及的是FCLK就是IF頻率。
電壓設置部分,有獨立的SOC電壓設定,而CLDO VDDG對于Intel用戶可能比較陌生,這個是內存控制器電壓。PLL電壓在提高BLCK時候才有用,一般可以不動。
X570的PBO精確自動超頻的上限被拉高,可以+200MHz。
供電設置里,除了CPU和mosfet的設置,還有大量的VDDSOC就是CIOD北橋的設置。
板上設備設置里除了網卡藍牙的開關,還可以設置各個插槽的PCIE速率,這是X570的獨有特色。
除開BIOS超頻,AMD也大幅更新了RyzenMaster軟件,用戶可以對核心開啟數量,各個電壓,內存和IF頻率等進行細致調節。
頻率穩定性/溫度/功耗和超頻
我們的測試環境為裸機平臺,環境為27度溫度設置的空調房,除了水冷240以外并無其他風扇。我們使用CineBench R20來測試處理器的頻率穩定,R20的測試分為2個階段,第一個階段是全核心負載的多線程測試,第二階段是單核心的單線程測試。R20相比R15測試時間更長,多線程部分超過28秒。Intel處理器測試我們分成兩個設置,第一個設置是默認設置,TDP在28秒內沒有限制,超過28秒就會被限制在95W,第二個設置是完全解除TDP的設置。
在默認設置9900K開始階段全核心頻率為4.7GHz,但在28秒之后就會降低到4-4.1GHz,使得功耗在95W以下,而解除功耗限制9900K在多核心測試可以保持全程 4.7GHz。而在后面的單線程測試,單核心的功耗遠遠低于95W的功耗墻,限制和不限制就沒太大的差別,基本都在4.8-5GHz范圍擺動。
3700X全核心在4.05-4.075GHz范圍,而單核心在4.275-4.325GHz范圍,雖然基礎頻率比2700X低,但實際無論是多核心還是單核心3700X都要比2700X高不少,甚至比2700X開PBO都要高。3800X全核心和單線程相比3700X基本高0.1GHz,其實差別不大。
超頻部分我先來說結論,基本盤大概是1.4V 4.3GHz,3700X的默認電壓在1.45V水平,超頻需要略微降低電壓,來降低功耗和溫度。之前2700X的基本盤是4.1GHz,Zen 2超頻性能還是有一定提升,但這個提升相信還是低于不少人的預期,之前在社交媒體和論壇不少人叫囂4.8/5GHz,雖然這些叫囂的人叫自己都不相信,但也就是這種氛圍抬高了人們的心理預期,使得人們還是期望應該有個4.5GHz以上的水平,究竟工藝提升了這么多,沒有4.5GHz實在說不過去。4.3GHz的頻率基本和boost頻率差不多,雖然手動超頻4.3GHz可以提升全核心,特別是Benchmark性能,但對日常使用和游戲并沒有什么提升,因為3700X/3800X日常和游戲的Boost頻率基本都高于4.3GHz。
對于什么叫超頻成功,不同人也有不同的標準,有人簡單跑R15通過就叫超頻成功,有人又要跑AIDA64 FPU或者Prime 95多長時間才叫通過,這其實都是有很大的誤區:Cinebench R15的負載過低,可以通過并不能說明什么問題,并不能保證其他日常應用的穩定。AIDA64 FPU或者Prime 95這樣的烤機基本就是燒AVX,對于HEDT平臺甚至是AVX512,負載相比日常應用又大太多,同樣也不能代表日常使用的情況,同樣也不合適。
我們超頻/溫度/功耗測試我選擇了2個測試場景,第一個是AIDA 64 6.0單烤FPU,但AIDA 64烤機是烤的AVX2,Intel平臺和Ryzen平臺性能存在較大差別,并不是類似負載情況,而是比較類似極限情況,而Keyshot 8測試,3700X和解除功耗限制的9900K性能幾乎一樣,更為合適直接比較,超頻一般能夠通過一個小時的Keyshot渲染測試,也基本可以保證日常使用的穩定。
上表Ryzen的幾個功耗讀數來自AIDA64的傳感器讀數,這個數據僅供參考,并不合適AMD和Intel平臺之間比較。整機功耗數據摘自功率計插座,我們使用的追風者1000W白金電源有90%以上的轉換效率,實際功耗大概需要打個9折,和RTX2080TI顯卡待機,1TB的NVME SSD和240水冷雖然也要消耗一些功耗,但這些功耗相對恒定,對于雙方比較還是基本公平的。
Keyshot 3700X整機功耗是172W,9900K無功耗限制是280W,兩者的性能幾乎一樣,3700X功耗低很多,這就驗證了AMD的說法,Zen 2 7nm的性能功耗比更好。
但這個只能代表是AMD Ryzen 臺積電7nm性能功耗比更好,并不能說AMD的工藝性能更好。Zen 2實際是沒什么超頻空間,全核心4.3GHz其實和默認Boost并沒太大差別,這樣的頻率同Intel平臺5GHz水平有很大的差距,雖然處理器設計會影響頻率,但達到頻率更多的還是由工藝決定,可見AMD 7nm相比Intel祖傳14FF++僅僅是有功耗方面的優勢,而在晶體管性能方面還是存在不少的差距。
首代的TSMC 7nm HD主要是針對密度和功耗優化,這樣的工藝在低頻表現好,功耗和溫度低,但如果加高電壓和頻率,功耗上升曲線會更為堵直。而高性能的HP工藝在高頻表現更好。這需要在下一代的Zen處理器才會實現,從樂觀的角度看,屆時AMD處理器的頻率應該有很大的提升空間。
3700X+X570待機功耗大概在70W以上,基本比3700X+X470或者9900K+Z390高10W以上,這主要是X570的南橋芯片組功耗更高,官方功耗是14W以上,而X470/Z390的南橋基本就5W級別。另外我們還發現在插拔USB設備時候,瞬時功耗有10瓦以上的變化,無論使用的直連還是南橋的USB都是如此,而在Intel平臺變化就沒有這樣明顯。這說明在插拔瞬間,CIOD或者南橋工作狀態和負載有明顯變化。
渲染性能測試
渲染性能測試我們首先測試是喜聞樂見的Cinebench R15,Ryzen 7 3700X的單線程性能相比2700X提升了16%,這其中頻率貢獻并不大,主要還是得益于效能的提升。R15現在看負載比較低,對穩定性要求也低,測試時間短,甚至不能不夠28秒觸發長時間TDP功耗限制。
Cinebench R20是R15的升級版,相比R15的負載更大,測試時間更長,對于穩定性有更高的要求,并且其中加入了AVX,雖然AVX比重很小,甚至不能觸動AVX Offset降頻。從R15和R20的數據看,3700X相比2700X單線程性能提升了15%,多核心性能更是提升了22%。3700X/3800X可以和9900K旗鼓相當了,Intel i5/i7由于沒有超線程的支持,Zen 2的優勢更為明顯。AMD在產品宣傳時候總是強調R15和R20性能,但這個性能主要是衡量SSE性能和多核心擴展性,甚至是單線程性能都不具有什么代表性,特別是不能代表游戲性能。
POVRAY測試也分為多線程和單線程。具體性能情況和前面的R15/R20類似,Ryzen表現優秀。
Keyshot 8具體測試場景如上圖,進行默認設置進行渲染。這個測試場景需要一個小時以上的時間,穩定性要求高于R15,和R20類似,是基于實際應用的測試,而非單純的基準測試,測試結果完成時間秒,結果越低越好。在這個基于實際應用的渲染場景中,Zen 2同樣大勝利,6C12T的3600大幅領先沒有超線程的9700和9700K,3700X相比TDP限制的9900K也有明顯優勢,超頻4.3GHz 3800X也超過了超頻5GHz的9900K,看來渲染領域現在成了AMD Zen 2的主場。
應用和AVX性能測試
Fritz Chess Benchmark是基于Fritz Chess算法的國際象棋程序,主要是考研分支預測性能,前面架構部分測試,Zen 2的單線程同頻性能相比Zen提升20%,分支預測能力大幅改善,9900K能夠超過Zen 2完成是憑借頻率優勢。
7ZIP是著名壓縮軟件,我們使用其自帶benchmark測試多線程和單線程性能,這個測試項目主要是考量整數性能,分支性能和多核延展性。3700X相比2700X在核心數一樣,頻率變化不大的情況下,性能提升20%,主要也是得益于動態分支預測器的改進,和上面的Fritz Chess Benchmark情況差不多。
X265 Benchmark是X265編碼程序,得出的結果是完成一次編碼的平均FPS,主要是考驗AVX2性能,Zen 2的AVX2性能大幅提升,6核心的3600就接近2700X水平,而3700X和3800X也反超有TDP限制的9900K。AVX由于負載極高,超線程的作用也不太明顯,9700/9700K相較9900K的差距也不算太大,更為吃實打實的核心數。
y-cruncher是利用AVX2甚至AVX512來算Pi的測試程序,我們選擇10億位進行測試。通常的Super P單線程計算100萬位就需要7-8秒,而y-cruncher利用SIMD來計算效能可以巨幅提升。y-cruncher測試負載和功耗極高,對穩定性要求也極高,處理器或者內存超頻稍有不穩定就會報錯,如本次測試9900K超頻的多線程部分都由于穩定性不夠而測試失敗。從單線程比較,3700X相比2700X快了43%提升巨大。Intel平臺由于Spectre/Meltdown漏洞補丁的影響不能開啟大分頁,性能大概有5%的負面影響。
由于y-cruncher支持AVX512,我們增加了HEDT的i9 9820X的測試,9820X完成多線程僅需34.5秒,AVX512的效能相比AVX2還有大幅上升,當然AVX512的功耗也是恐怖的,9820X 4.2GHz的AVX512功耗甚至會到達380W的水平。不過現在支持AVX512的都是行業軟件,如Adobe系也只是用到AVX2,因此這個問題對于一般消費者而言并沒什么影響。
游戲性能測試
在游戲性能測試之前,我們先說說CPU和GPU對于游戲性能的影響,游戲性能會存在一個CPU FPS,一個GPU FPS,具體游戲的FPS是由這兩者的下限決定。
對于游戲而言,游戲畫面越好,畫質和分辨率設置越高,整體瓶頸會更為傾向GPU,對于LOL和CSGO這種畫面技術簡單,顯卡要求低的游戲,對于CPU更為敏感。我們選取了8個高人氣的游戲來進行測試,既有CSGO這樣的DX9老游戲,也有古墓麗影這樣的RTX AAA大作。并且在這8個游戲中,其中文明6、全境封鎖2、刺客信條奧德賽是AMD合作的Ryzen優化游戲,而Intel優化的只有全面戰爭三國一個。
首先我們先看個具體范例:地平線4是Windows UWP平臺第一方賽車游戲大作,我們使用1080P最高畫質 4X MSAA使用游戲自帶benchmark進行測試。9900KF的實際游戲性能曲線是由GPU性能的黃線決定,而CPU性能的藍線高高在上。
處理器換成2700X,處理器性能的藍線低了很多,直接壓制住GPU黃線,平均FPS也由121FPS下降到了114FPS,2700X的CPU性能明顯拖累了游戲性能。
所有的Intel的CPU FPS都沒有給游戲性能帶來瓶頸,最終平均FPS都為122FPS。Zen 2的CPU FPS相比相比Zen有明顯提升,從140FPS上升到170FPS左右,但CPU還是對游戲性能有略微的限制。
古墓麗影崛起雖然加入了對RTX的支持,使得其顯卡負載大大提升,但作為AAA對于處理器性能依然敏感。我們測試使用1080P RTX ON MAX的畫質設定。古墓麗影暗影和地平線4一樣,同樣有CPU性能測試數據。
CPU性能低就會壓低GPU的性能表現,雖然3700X的游戲CPU性能比2700X提升了24%,但在中段每幀的CPU耗時還是高于GPU,這就說明了CPU性能拖累了GPU。
而9900K的每幀CPU耗時全部低于GPU,這說明瓶頸完全在顯卡,CPU性能沒有對游戲性能有任何拖累。
絕地求生雖然比17/18涼了不少,但終究還是最高人氣的PC游戲(LOL除外)。之前我們測試都是采用的1080p MAX的設定,但實際上大多玩家都是采用紋理,抗鋸齒和視野距離最高,其他最低的設定,這樣可以在視覺效果和性能方面獲得平衡,同時也更為容易索敵。另外一方面也可以獲得更好的性能和更為穩定的FPS。在這樣的畫質設定下,GPU占用率基本在60%左右,明顯吃不滿,整體的瓶頸就被轉移到CPU。而在2K分辨率全最高特效,GPU占用率則基本在95%以上。我們測試方法是選擇Miramar沙漠地圖的回放,使用FRAPS記錄2分鐘到10分鐘的游戲性能,分別使用2K全最高和2K采用紋理,抗鋸齒和視野距離最高,其他最低的設定進行測試。
在全特效的時候顯卡依然還是瓶頸,各個CPU的FPS基本沒有什么差距。但將畫質設置成1440P 紋理抗鋸齒視野距離最高 其他最低的時候,不同處理器之間的差距就拉大開來 。
9900K/9700K平均FPS在240到250水平,最低FPS級別也在130FPS以上。而2700X平均FPS 170FPS不到,最低FPS僅有90的水平。3600/3700X著基本有210FPS左右水平,相比2700X提升了接近50FPS。
9900K超頻到5GHz,平均FPS可以從250提升到266,這說明CPU上面依然有瓶頸。雖然平均FPS都在144以上,但最低FPS還是存在明顯差別,更高的最低FPS在電競顯示器上還是會有更好的體驗。
文明6我們使用游戲(非資料片)自帶的AI Benchmark進行測試,結果為每回合AI計算時間,結果越小越好,注意文明6最近修改了AI算法,比之前的測試要快,并無可比性。
文明6大概可以吃7個核心,其中一個吃滿,雖然AI計算理論上并行度可以很高,但文明6本質還是單核心游戲,游戲性能基本和單核心性能成正比。
CSGO是采用的十幾年前的Source引擎,還是采用的DX9 API,對于顯卡要求不高,但對于處理器性能極其敏感。有可能有人認為200FPS和300FPS并沒什么差別,反正都比顯示器的刷新率高為什么,但CSER卻對FPS有種幾乎偏執的追求,雖然這種追求我并不能理解。我們使用控制臺的timedemo命令行進行測試,測試場景為Dust 2。
雖然CSGO是個DX9的古董游戲,但還是可以利用6個以上的核心,其中一個核心執行主要任務占用幾乎可以吃滿,因此其同時吃單線程和多線程性能。
全面戰爭三國是全面戰爭系列的最新作 ,本作將游戲背景移到中國的三國時期,在最近一段時間一直都位列Steam游戲銷量排行的前列。全面戰爭在戰略界面是回合制,而在戰術界面是RTS,同屏數千甚至上萬人,對于處理器有比較高的負載。我們使用游戲自帶的Benchmark進行測試,設定的是1080P最高畫質。另外需要提及的是本作是Intel處理器的優化游戲,可以充分利用8個核心線程。
全戰三國的任務負載較為均衡,對于多線程能力更為看重,因此只有6C6T的9400F性能最差,不過還是得益于架構優勢,Ryzen 5 3600性能還是優于2700X,3700X相比2700X也有10%的性能提升。
刺客信條奧德賽是Ubisoft開發的刺客信條的最新作,我們使用1080p MAX畫質,使用游戲自帶的benchmark進行測試。奧德賽也是Ryzen優化游戲,可以用到12個以上的線程,對于多核心利用很充分。奧德賽測試minFPS很不穩定,我們不予統計。
在奧德賽的Benchmark中,Zen 2的性能超過了6C6T的i5,但相比i7/i9還是差距明顯。
全境封鎖2是Massive工作室開發的戰術射擊RPG游戲,和前作一樣,采用自行研發的Snowdrop引擎,我們使用1080P Ultra畫質,使用游戲自帶Benchmark進行測試。本作也是Ryzen優化游戲。本作對多核心優化十分充分,基本16個線程都有合理負載。
雖然是Ryzen優化游戲,但Ryzen并沒占到什么便宜。i9和i7優勢明顯,不過3700X相比2700X還是有巨大的進步,提升了16FPS,入門級的Ryzen 5 3600相比2700X都優勢明顯,并且以1FPS的優勢戰勝了i5 9400。
其實游戲測試整體結果有點超出我的想象,不僅是CSGO/絕地求生3MAX畫質不同處理器有差距,就如全境封鎖2、古墓陰影暗影、刺客信條奧德賽這樣極端吃顯卡的AAA游戲也有明顯差距。但這個測試是以RTX 2080TI為平臺,使得CPU需要保持更高性能,才不至于拖GPU后腿。但這樣的問題對于有RTX2080TI+144Hz顯示器的用戶才會特別明顯。如果你是使用的2080或者以下顯卡,再或者使用2K甚至4K顯示器的時候,瓶頸又依然會回到顯卡段上。這個時候使用Zen 2還是Intel i7/i9差別就將會縮小。
9700K相比9900K在游戲性能方面還要略勝一籌,主要是9900K的超線程消耗了一些資源。
9700相比9700K差距也小于預期,9700雖然不能超頻,TDP也僅有65W,但游戲并不會觸及TDP墻,實際游戲頻率基本也在4.4GHz以上。
Ryzen 7 2700X的游戲性能實話,明顯低于我的預期,在絕大多數游戲中相比9xx元的i5 9400F都有明顯的差距。
但Zen 2新架構3600性能大幅提升,和9400F互有勝負,打得你來我往。
3700X的游戲性能大概是9700F的95%,3800X我們也進行了測試,游戲頻率大概高75-100MHz,實際游戲性能并沒太明顯差別,因此我就沒額外列出。
3700X/3800X全核心超頻可以超到4.3GHz,但這個頻率低于游戲時候默認Boost的加速頻率,超頻4.3GHz反而會降低游戲性能,因此并無測試的意義。
Zen 2的購買建議
之前的Zen/Zen+的微架構效能基本就是Haswell的水平,而Zen 2將架構效能做到了Skylake的級別,甚至略有超越,可以說有十分大的進步。但在芯片系統整體架構上,Zen 2選擇了成本和擴展性優先,Chiplet + iCOD的結構雖然容易擴展,成本上比單個大核心占優,但導致存儲體系效能受到很大影響,這些的設計是妥協的結果。這樣妥協是由策略決定的。繼續提高效能既然困難,不如用更低的成本來擴展規模,達成更多的核心,這樣在市場營銷上更為方便。
總有人強調IPC,Zen 2的IPC已經達到了Skylake的級別,但性能差距在頻率,Intel:我既然頻率吊打你,為什么要跟你比同頻?這個頻率的差距主要就在工藝,目前的TSMC 7nm是首代7nm工藝,主要是針對密度和功耗優化,雖然在低頻功耗比較很好,但在高頻無能。如果AMD想要上高頻,還要待到第二代7nm HP工藝。
Ryzen 5 3600的價位在1500元左右,配合500元級別的B450M,平臺整體成本在2000元水平。這個價位基本是Intel的空白,Intel下面是9400F+B360(1000+500),上面是8700+B360(2000+500),而類似價位僅僅只有尷尬的9600K,但9600K配合便宜的B360就不能超頻,配合Z370/Z390平臺的整體成本就過高。Ryzen 5 3600在有更好的多線程性能的同時,也可以提供i5水平的游戲性能,還是有一定的競爭力。
Ryzen 5 3600X相比3600要貴400,雖然我沒實際測試過,但參考3700X和3800X的情況,實際Boost頻率相比3600也不會有太大的差別,一般不予推薦。
Ryzen 7 3700X和i7 9700F價格定位十分接近,優點在于更好的多線程性能(特別是渲染),還有超頻的可玩性,但在游戲性能上相比9700F還是有差距(大概5%)。主板平臺方面我們推薦比較高供電規格的B450或者上一代的X470。
3700X和3800X的關系比較類似2700和2700X,但其之間的頻率差距更小,Ryzen 7 3800X相比3700X要貴上600元,但全核心和單核心頻率基本只有0.1GHz的優勢,性能上沒有明顯的差別,不與推薦。
Ryzen 7 3900X/3950X基本就是在桌面平臺實現了以往X399這樣HEDT級別的性能,合適對計算密度要求很高的用戶,特別是設計類行業用戶,如3D設計和視頻處理,但12C/16C處理器的功耗會更高,因此我們推薦使用高規格的X570主板,就如我們本次的測試平臺ROG CROSSHAIR VIII HERO (WI-FI)。








