
AI芯片哪家強?現在,有直接的對比與參考了。
英國一名資深芯片工程師James W. Hanlon,盤點了當前十大AI訓練芯片。
并給出了各個指標的橫向對比,也是目前對AI訓練芯片最新的討論與梳理。
其中,華為昇騰910是中國芯片廠商唯一入選的芯片,其性能如何,也在這一對比中有了展現。
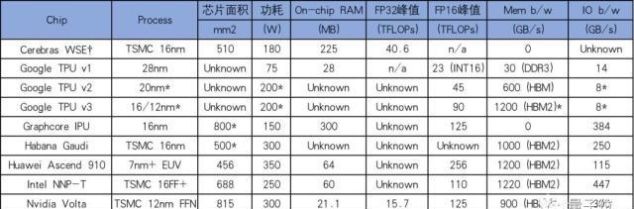
△ *代表推測,代表單芯片數據。
Cerebras Wafer-Scale Engine

這一芯片于今年8月份正式面世,被稱為“史上最大AI芯片”,名為“晶圓級引擎”(Cerebras Wafer Scale Engine,簡稱WSE)。
其最大的特征是將邏輯運算、通訊和存儲器集成到單個硅片上,是一種專門用于深度學習的芯片。
一舉創下4項世界紀錄:
晶體管數量最多的運算芯片:總共包含1.2萬億個晶體管。雖然三星曾造出2萬億個晶體管的芯片,卻是用于存儲的eUFS。芯片面積最大:尺寸約20厘米×23厘米,總面積46225平方毫米。片上緩存最大:包含18GB的片上SRAM存儲器。運算核心最多:包含410,592個處理核心之所以能夠有如此亮眼的數據,直接得益于其集成了84個高速互連的芯片,單個芯片在FP32上的峰值性能表現為40 Tera FLOPs,芯片功率達15千瓦,與AI集群相當。
片上緩存也達到了18GB,是GPU緩存的3000倍;可提供每秒9PB的內存帶寬, 比GPU快10,000倍。
晶片規模集成,并不是一個新的想法,但產量、功率傳輸和熱膨脹相關的問題使其很難商業化。在這些方面,Cerebras都給出了相應的解決辦法:
為了解決缺陷導致良率不高的問題,Cerebras在設計的芯片時候考慮了1~1.5%的冗余,添加了額外的核心,當某個核心出現問題時將其屏蔽不用,因此有雜質不會導致整個芯片報廢。Cerebras與臺積電合作發明了新技術,來處理具有萬億加晶體管芯片的刻蝕和通訊問題。在芯片上方安裝了一塊“冷卻板”,使用多個垂直安裝的水管直接冷卻芯片。Cerebras公司由Sean Lie(首席硬件架構師)、Andrew Feldman(首席執行官)等人于2016年創立。后者曾創建微型服務器公司SeaMicro,并以3.34億美元的價格出售給AMD。
該公司在加州有194名員工,其中包括173名工程師,迄今為止已經從Benchmark等風投機構獲得了1.12億美元的投資。
拓展閱讀:史上最大AI芯片誕生:462平方厘米、40萬核心、1.2萬億晶體管,創下4項世界紀錄
Google TPU(v1、v2、v3)
Google TPU系列芯片正式發布于2016年,第一代芯片TPU v1只用于推理,而且只支持整數運算。
通過在PCIe-3之間發送指令來執行矩陣乘法和應用激活函數,從而為主機CPU提供加速,節省了大量的設計和驗證時間。其主要數據為:
芯片面積331平方毫米,28nm制程頻率為700 MHz,功耗28-40W片上存儲為28 MB SRAM:24MB 用于激活,4MB 用于累加器芯片面積比例:35%用于內存,24%用于矩陣乘法單元,剩下的41%面積用于邏輯。256x256x8b收縮矩陣乘法單元(64K MACs/cycle)Int8和 INT16算法(峰值分別為92和23 TOPs/s)IO數據:
可以通過兩個接口訪問8 GB DDR3-2133 DRAM,速度為34 GB/sPCIe-3x16 (14 GBps)2017年5月,Google TPU v2發布,改進了TPU v1的浮點運算能力,并增強了其內存容量、帶寬以及HBM 集成內存,不僅能夠用于推理,也能夠用于訓練。其單個芯片的數據如下:
20nm制程,功耗在200-250W(推測)BFloat16上性能表現為45 TFLOPs,也支持 FP32具有標量和矩陣單元的雙核集成4塊芯片后,峰值性能為180 TFLOPs單核數據:
128x128x32b收縮矩陣單元(MXU)8GB專用HBM,接入帶寬300 GBpsBFloat16上的最大吞吐量為22.5 TFLOPsIO數據:
16Gb HBM集成內存,600 GBps帶寬(推測)PCIe-3 x8 (8 GBps)Google TPU v2發布一年之后,Google再度發布新版芯片——TPU v3。

但關于TPU v3的細節很少,很可能只是對TPU v2一個漸進式改版,性能表現翻倍,增加了HBM2內存使容量和帶寬翻倍。其單個芯片的數據如下:
16nm或12nm制程,功耗估計在200WBFloat16的性能為105 TFLOPs,可能是MXUs的2倍到4倍每個MXU都能訪問8GB的專用內存集成4個芯片后,峰值性能420 TFLOPsIO數據:
32GB的HBM2集成內存,帶寬為1200GBps (推測)PCIe-3 x8 (8 GBps)(推測)拓展閱讀:想了解TPU 3.0?Jeff Dean推薦看看這段視頻
Graphcore IPU
Graphcore成立于成立于2016年,不僅備受資本和業界巨頭的青睞,還頗受業內大佬的認可。
2018年12月,宣布完成2億美元的D輪融資,估值17億美元。投資方有寶馬、微軟等業界巨頭,還有著名的風投公司Sofina、Atomico等。
AI巨頭Hinton、DeepMind創始人哈薩比斯,都直接表達了贊美。
Graphcore IPU是這家公司的明星產品,其架構與大量具有小內存的簡單處理器高度并行,通過一個高帶寬的“交換”互連連接在一起。

其架構在一個大容量同步并行(BSP)模型下運行,程序的執行按照一系列計算和交換階段進行。同步用于確保所有進程準備好開始交換。
BSP模型是一個強大的編程抽象,用于排除并發性風險,并且BSP的執行,允許計算和交換階段充分利用芯片的能源,從而更好地控制功耗。可以通過鏈接10個IPU間鏈路來建立更大的IPU芯片系統。其核心數據如下:
16nm制程,236億個晶體管,芯片面積大約為800平方毫米,功耗為150W,PCIe卡為300 W1216個處理器,在FP32累加的情況下,FP16算法峰值達到125 TFLOPs分布在處理器核心之間有300 MB的片上內存,提供45 TBps的總訪問帶寬所有的模型狀態保存在芯片上,沒有直接連接DRAMIO數據:
2x PCIe-4的主機傳輸鏈接10倍的卡間IPU鏈接共384GBps的傳輸帶寬單核數據:
混合精度浮點隨機算法最多運行六個線程拓展閱讀:成立兩年估值17億美元,這家Hinton點贊的AI芯片公司獲寶馬微軟投資
Habana Labs Gaudi
Habana Labs同樣成立于2016年,是一家以色列AI芯片公司。
2018年11月,完成7500萬美元的B輪募資,總募資約1.2億美元。
Gaudi芯片于今年6月亮相,直接對標英偉達的V100。
其整體的設計,與GPU也有相似之處,尤其是更多的SIMD并行性和HBM2內存。

芯片集成了10個100G 以太網鏈路,支持遠程直接內存訪問(RDMA)。與英偉達的NVLink或OpenCAPI相比,這種數據傳輸功能允許使用商用網絡設備構建大型系統。其核心數據如下:
TSMC 16 nm制程(CoWoS工藝),芯片尺寸大約為500平方毫米異構架構:GEMM操作引擎、8個張量處理核(TPCs)SRAM內存共享PCIe卡功耗為200W,夾層卡為300W片上內存未知TPC核心數據:
VLIW SIMD并行性和一個本地SRAM內存支持混合精度運算:FP32、 BF16,以及整數格式運算(INT32、INT16、INT8、UINT32、UINT8)隨機數生成、超越函數:Sigmoid、Tanh、GeLUIO數據:
4x 提供32 GB的HBM2-2000 DRAM 堆棧, 整體達1 TBps芯片上集成10x 100GbE 接口,支持融合以太網上的 RDMA (RoCE v2)PCIe-4 x16主機接口Huawei Ascend 910
華為昇騰910,同樣直接對標英偉達V100,于今年8月份正式商用,號稱業內算力最強的AI訓練芯片。主打深度學習的訓練場景,主要客戶面向AI數據科學家和工程師。

其核心數據為:
7nm EUV工藝,456平方毫米集成4個96平方毫米的 HBM2棧和 Nimbus IO處理器芯片32個達芬奇內核FP16性能峰值256TFLOPs (32x4096x2) ,是 INT8的兩倍32 MB的片上 SRAM (L2緩存)功耗350W互聯和IO數據:
內核在6 x 4的2d網格封包交換網路中相互連接,每個內核提供128 GBps 的雙向帶寬4 TBps的L2緩存訪問1.2 TBps HBM2接入帶寬3x30GBps 芯片內部 IOs2 x 25 GBps RoCE 網絡接口單個達芬奇內核數據:
3D 16x16x16矩陣乘法單元,提供4,096個 FP16 MACs 和8,192個 INT8 MACs針對 FP32(x64)、 FP16(x128)和 INT8(x256)的2,048位 SIMD 向量運算支持標量操作拓展閱讀:華為算力最強AI芯片商用:2倍于英偉達V100!開源AI框架,對標TensorFlow和PyTorch
Intel NNP-T
這是Xeon Phi之后,英特爾再次進軍AI訓練芯片,歷時4年,壕購4家創業公司,花費超過5億美元,在今年8月份發布。
神經網絡訓練處理器NNP-T中的“T”指Train,也就是說這款芯片用于AI推理,處理器代號為Spring Crest。
NNP-T將由英特爾的競爭對手臺積電(TSMC)制造,采用16nm FF 工藝。
NNP-T有270億個16nm晶體管,硅片面積680平方毫米,60mmx60mm 2.5D封裝,包含24個張量處理器組成的網格。

核心頻率最高可達1.1GHz,60MB片上存儲器,4個8GB的HBM2-2000內存,它使用x16 PCIe 4接口,TDP為150~250W。
每個張量處理單元都有一個微控制器,用于指導是數學協處理器的運算,還可以通過定制的微控制器指令進行擴展。
NNP-T支持3大主流機器學習框架:TensorFlow、PyTorch、PaddlePaddle,還支持C 深度學習軟件庫、編譯器nGraph。
在算力方面,芯片最高可以達到每秒119萬億次操作(119TOPS),但是英特爾并未透露是在INT8還是INT4上的算力。
作為對比,英偉達Tesla T4在INT8上算力為130TOPS,在INT4上為260TOPS。
拓展閱讀:英特爾首款AI芯片終于發布:訓練推理兩用,歷時4年花費5億美元買來4家公司
英偉達Volta架構芯片
英偉達Volta,2017年5月公布,從 Pascal 架構中引入了張量核、 HBM2和 NVLink 2.0。

英偉達V100芯片就是基于此架構的首款GPU芯片,其核心數據為:
TSMC 12nm FFN工藝,211億個晶體管,面積為815平方毫米功耗為300W,6 MB L2緩存84個SM,每個包含:64個 FP32 CUDA 核,32個 FP64 CUDA 核和8個張量核(5376個 FP32核,2688個 FP64核,672個 TCs)。單個Tensor Core每時鐘執行64個FMA操作(總共128 FLOPS),每個SM具有8個這樣的內核,每個SM每個時鐘1024個FLOPS。相比之下,即使采用純FP16操作,SM中的標準CUDA內核只能在每個時鐘產生256個FLOPS。每個SM,128 KB L1數據緩存 / 共享內存和4個16K 32位寄存器。IO數據:
32 GB HBM2 DRAM,900 GBps帶寬300 GBps的NVLink 2.0英偉達Turing架構芯片
Turing架構是對Volta架構的升級,于2018年9月發布,但 CUDA 和張量核更少。

因此,它的尺寸更小,功率也更低。除了機器學習任務,它還被設計用來執行實時射線追蹤。其核心數據為:
TSMC 12nm FFN工藝,面積為754平方米,186億個晶體管,功耗260W72個SM,每個包含:64個 FP32核,64個 INT32核,8個張量核(4608個 FP32核,4608個 INT32核和576個 TCs)帶有boost時鐘的峰值性能:FP32上為16.3 TFLOPs、FP16上為130.5 TFLOPs、INT8上為261 TFLOPs、INT4上為522 TFLOPs片上內存為24.5 MB,在6MB的 L2緩存和256KB 的 SM 寄存器文件之間基準時鐘為1455 MHzIO數據:
12x32位 GDDR6存儲器,提供672 GBps 聚合帶寬2x NVLink x8鏈接,每個鏈接提供多達26 GBps 的雙向速度.






 EP2C8F256I8n
EP2C8F256I8n
EP2C8F256C8N
EP2C8F256C6N
EP1C12F256I7N
EP1C12F324C7N
EP1C12F324C8N
EP1C12F256C7N
EP1C12F256C8N
EPM3512AFC256-7N
EPM3512AFC256-10N
EPM3512AQC208-7N
EPM3512AQI208-10N
EPM3512AQC208-10N
EPM3512AFI256-10N
EPM3512AFC256-10
EP1K50TC144-3N
EP1K50QC208-1N
EP1K50TC144-1N
EP1K50FI256-1N
EP1K50FI256-3N
EP1K50FC484-3Q
EP1K50FC484-3N
EP1K50FC484-1N
EP1K50FC256-3N
EP1K50FC256-1N
EP1K50FC256-2N
EP4CE6E22C7N
EP4CE6F17A7N
EP4CE6E22I8N
EP4CE6F17I8LN
EP4CE6F17C6N
EP4CE6F17I8N
EP4CE6U14I7N
EP4CE6E22I6N
EP4CE6F17I6N
EP4CE6E22C8N
EP4CE6F17C8LN
EP4CE6E22C8LN
EP3C5U256I7N
EP3C5F256C7N
EP3C5F256C6N
EP3C5E144C8N
EP3C5E144A7N
EP3C5E144C7N
EP3C5F256I7N
EP3C5E144I7N
EP3C5U256C8N
EP3C5F256A7N
EP3C5U256A7N
EP3C5U256C6N
EP3C5U256C7N
EP4CE22E22I7N
EP4CE22F17C8N
EP4CE22F17A7N
EP4CE22E22A8N
EP4CE22E22A7N
EP4CE22E22A6N
EP4CE22E22I6N
EP4CE22F17C6N
EP4CE22E22I8N
EP4CE22U14I7N
EP4CE22F17I8LN
EP4CE22F17C7N
EP3C10U256I6N
EP3C10F256A7N
EP3C10F256C7N
EP3C10F256C8N
EP3C10U256I8N
EP3C10E144C7N
EP3C10E144C8N
EP3C10U256C7N
EP3C10U256C6N
EP3C10U256A7N
EP3C10E144A7N
EP3C10F256I8N
EP3C10U256C8N
EP3C10F256I7N
EP3C10U256I7N
EP1C4F400C6N
EP1C4F324C7N
EP1C20F400C6N
EP1C20F324C6N
EP1C20F324C8N
EP1C20F324C7N
EP1C20F400C8N
EP2C35F672C8N
EP2C5T144I8N
EP2C5Q208C8N
EP2C35F672I8N
EP2C50F672I8N
EP2C50U484I8N
EP2C35U484C8N
EP2C8Q208I8N
EP4CE40F23I6N
EP4CE30F23I8LN
EP4CE15F23I6N
EP4CE115F23I7N
EP4CE55F23I9N
EP4CE15F23I7N
EP4CE75F23C7N
公司:深圳振華航空半導體有限公司
公司熱線:400-8855-170
聯系方式:18926507567 QQ:549400747
公司網址:www.zhjgic.com
公司主營軍工物料和存儲芯片,誠信經營,大量現貨庫存,歡迎您隨時咨詢








