
對SPI或I2C進行編碼需要額外的微控制器參考模型的性能結果
發布時間:2021/11/20 20:14:31 訪問次數:118
為了提高準確性,數據集變得越來越大,越來越復雜,因此需要更大、更復雜的模型。
這就推動了提高計算性價比的需求,與基于GPU的EC2實例相比,新的Amazon EC2 DL1實例承諾能顯著降低訓練成本。我們預計,對于廣泛的客戶來說,這一優點將使云端的AI模型訓練無論在成本競爭力還是可訪問性方面都較以往有大幅提升。
醫療保健進步的眾多技術中,使用機器學習和深度學習基于醫學成像數據對疾病進行診斷.我們的海量數據集需要及時,高效的訓練,為苦心鉆研一些最亟待解決的醫學謎題的研究人員提供幫助。

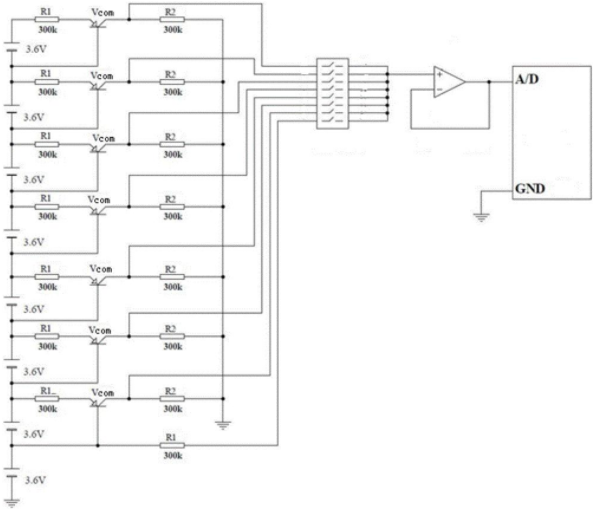
一般的共享電源和數據接口經過編碼,可減少信號直流成分,從而在發送交流信號成分時簡化系統設計。但是,許多數字輸出傳感器接口(例如,SPI和I2C)尚未經過編碼,具有可變的信號直流成分,因此不是共享數據和電源設計的自然之選。
對SPI或I2C進行編碼需要額外的微控制器,這會增加解決方案的成本和尺寸。
為了免去編碼和額外增加微控制器的麻煩,設計人員必須嘗試采用多快好省的辦法,這就需要仔細設計和模擬工程電源電路。工程電源電路由電感、電容和保護電路組成,一起構成了一個濾波器。
Habana Gaudi加速器的Amazon EC2 DL1實例所具備的顯著性價比優勢,在未來很可能會成為AWS計算集群的有力補充,隨著Habana Labs的不斷發展,支持的運營商覆蓋范圍越來越大,有潛力擴展來支持更多的企業用例,從而進一步節省成本。
相較于Habana在TensorFlow模型的表現,Habana 在PyTorch模型上的性能略低(吞吐量和訓練時間)。我們在SynapseAI用戶指南中以及GitHub上的參考模型中記錄了已知限制。
此外,我們還在Habana開發人員網站上發布了參考模型的性能結果。Habana團隊致力于在后續發行版中不斷提升易用性和性能。

(素材來源:ttic和eccn.如涉版權請聯系刪除。特別感謝)
為了提高準確性,數據集變得越來越大,越來越復雜,因此需要更大、更復雜的模型。
這就推動了提高計算性價比的需求,與基于GPU的EC2實例相比,新的Amazon EC2 DL1實例承諾能顯著降低訓練成本。我們預計,對于廣泛的客戶來說,這一優點將使云端的AI模型訓練無論在成本競爭力還是可訪問性方面都較以往有大幅提升。
醫療保健進步的眾多技術中,使用機器學習和深度學習基于醫學成像數據對疾病進行診斷.我們的海量數據集需要及時,高效的訓練,為苦心鉆研一些最亟待解決的醫學謎題的研究人員提供幫助。
一般的共享電源和數據接口經過編碼,可減少信號直流成分,從而在發送交流信號成分時簡化系統設計。但是,許多數字輸出傳感器接口(例如,SPI和I2C)尚未經過編碼,具有可變的信號直流成分,因此不是共享數據和電源設計的自然之選。
對SPI或I2C進行編碼需要額外的微控制器,這會增加解決方案的成本和尺寸。
為了免去編碼和額外增加微控制器的麻煩,設計人員必須嘗試采用多快好省的辦法,這就需要仔細設計和模擬工程電源電路。工程電源電路由電感、電容和保護電路組成,一起構成了一個濾波器。
Habana Gaudi加速器的Amazon EC2 DL1實例所具備的顯著性價比優勢,在未來很可能會成為AWS計算集群的有力補充,隨著Habana Labs的不斷發展,支持的運營商覆蓋范圍越來越大,有潛力擴展來支持更多的企業用例,從而進一步節省成本。
相較于Habana在TensorFlow模型的表現,Habana 在PyTorch模型上的性能略低(吞吐量和訓練時間)。我們在SynapseAI用戶指南中以及GitHub上的參考模型中記錄了已知限制。
此外,我們還在Habana開發人員網站上發布了參考模型的性能結果。Habana團隊致力于在后續發行版中不斷提升易用性和性能。
(素材來源:ttic和eccn.如涉版權請聯系刪除。特別感謝)
 相關技術資料
相關技術資料- 11-28最新集成傳感激光測距模塊規格參數技術應用
- 11-28Supermicro NVIDIA HGX B200系統參數應用設
- 11-28新一代 ToF 激光測距傳感器詳細探討
- 11-28全新 Riedon™ 功率電阻產品系列
- 11-28分流電阻的檢測原理及市場格局
- 11-28前沿技術AI輔助診斷應用新進展
- 11-2712位模數轉換器 (ADC)參數特點技術封裝
- 11-27三角函數加速器 (TMU)系列
- 11-27單芯片“艙行泊”一體化方案探究
- 11-27CoolSiC肖特基二極管技術參數應用設計
- 11-27納微GaN Safe系列NV6515(650V,32mΩ max)IC
- 11-27臨界導通模式(CrM)詳情
 公網安備44030402000607
公網安備44030402000607





